PDFtoPDF.ai gegen PDF AI

PDFtoPDF.ai
Ideal Für
Konvertieren von gescannten Büchern in digitalen Text
Verbesserung der Effizienz der Dokumentenverarbeitung
Archivierung von Archivmaterialien
Vereinfachung der Datenextraktion
Wichtige Stärken
Erhält die ursprüngliche Formatierung
Reduziert manuelle Dateneingabe
Optimiert den Dokumentenworkflow
Kernfunktionen
Deep Learning OCR-Technologie
genaue Texterkennung
Erhaltung des Originalformats
schnelle Verarbeitungsgeschwindigkeiten
benutzerfreundliche Oberfläche
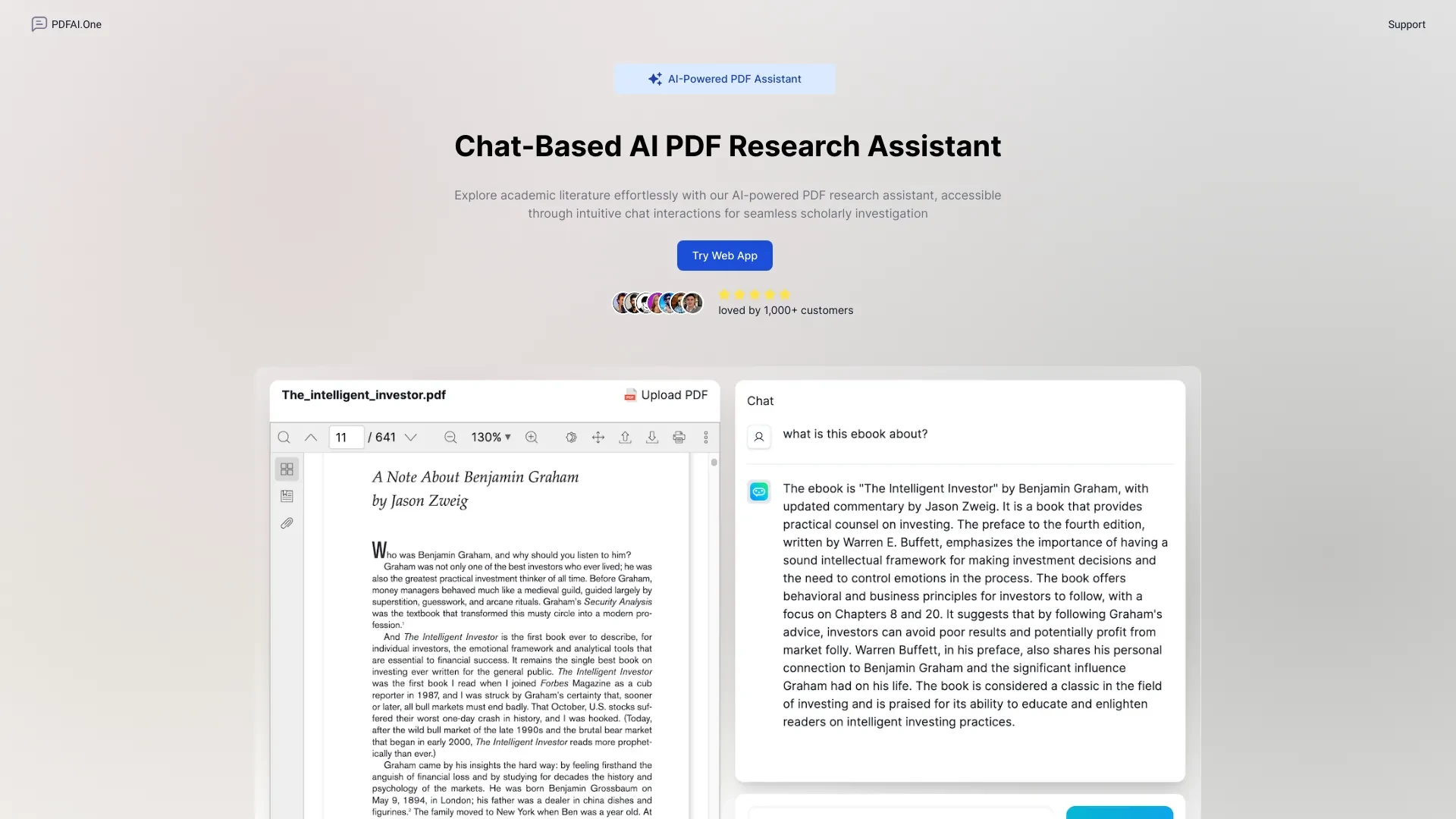
PDF AI
Ideal Für
Zugriff auf wissenschaftliche Artikel
Analyse von Forschungsarbeiten
Zusammenfassung umfangreicher Dokumente
Extrahierung wichtiger Informationen aus PDFs
Wichtige Stärken
Spart Zeit bei der Forschung
bietet sofortige Einblicke
verbessert das Verständnis komplexer Materialien
Kernfunktionen
KI-gesteuerten PDF-Assistent
intuitive Chat-Interaktionen
schnelle Einsichten-Retrieval
Fähigkeit zur Analyse großer PDF-Dokumente bis zu 20 MB
nahtlose Integration in Forschungsabläufe