Ideal Para
Acelerando a implantação de modelos
Aumentando a responsividade de aplicações
Gerenciando eficientemente operações de ML em larga escala
Otimizando fluxos de trabalho baseados em IA
Forças Chave
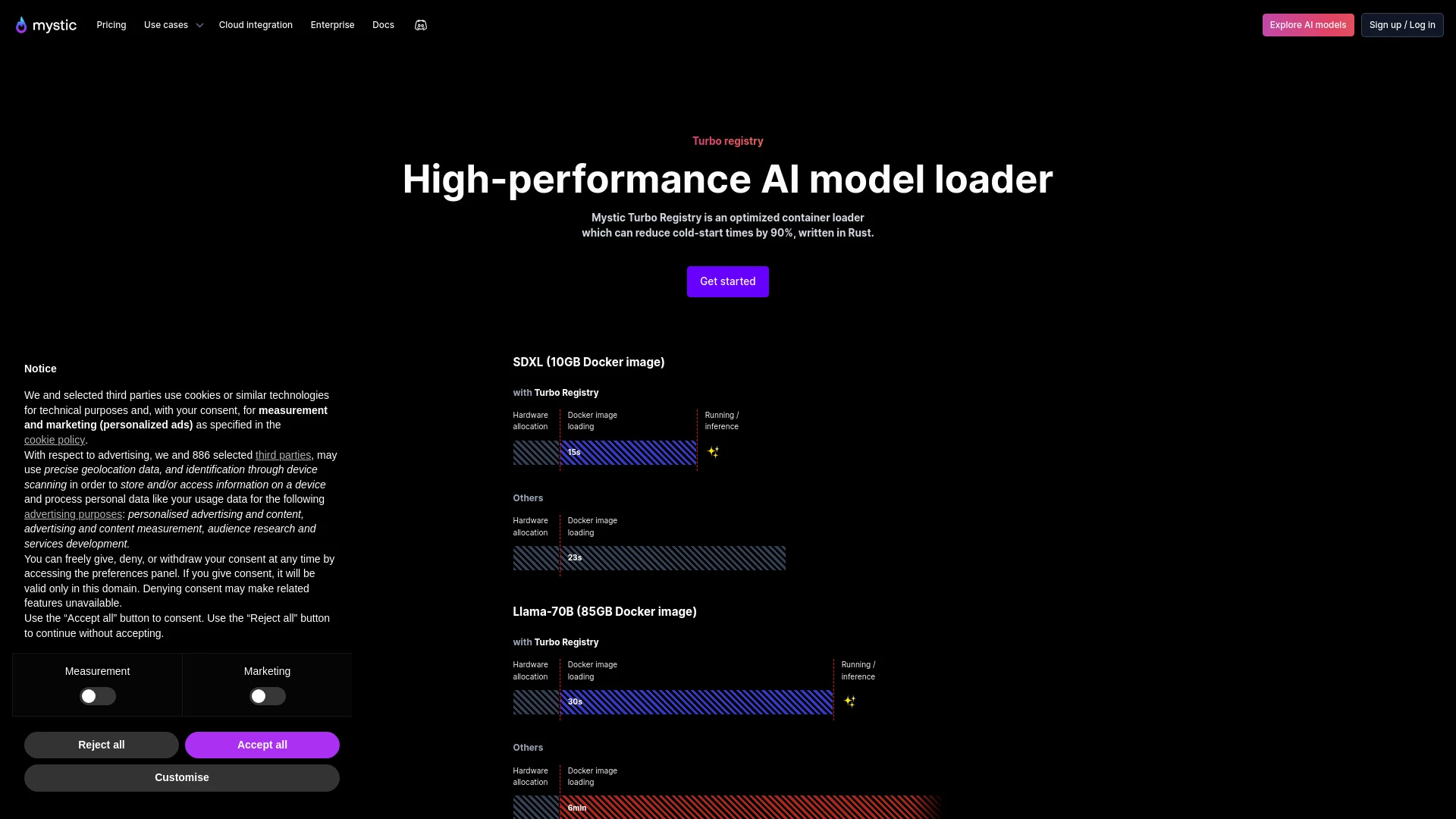
Reduz significativamente o tempo de inicialização
Aumenta a velocidade geral de carregamento do modelo
Melhora a eficiência da aplicação
Recursos Principais
Loading de contêiner otimizado
Carregamento de modelo de alto desempenho
Construído em Rust para eficiência aprimorada
Integração perfeita em pipelines de ML
Redução de tempos de inicialização a frio