Hypercharge AI
0
Ideal Para
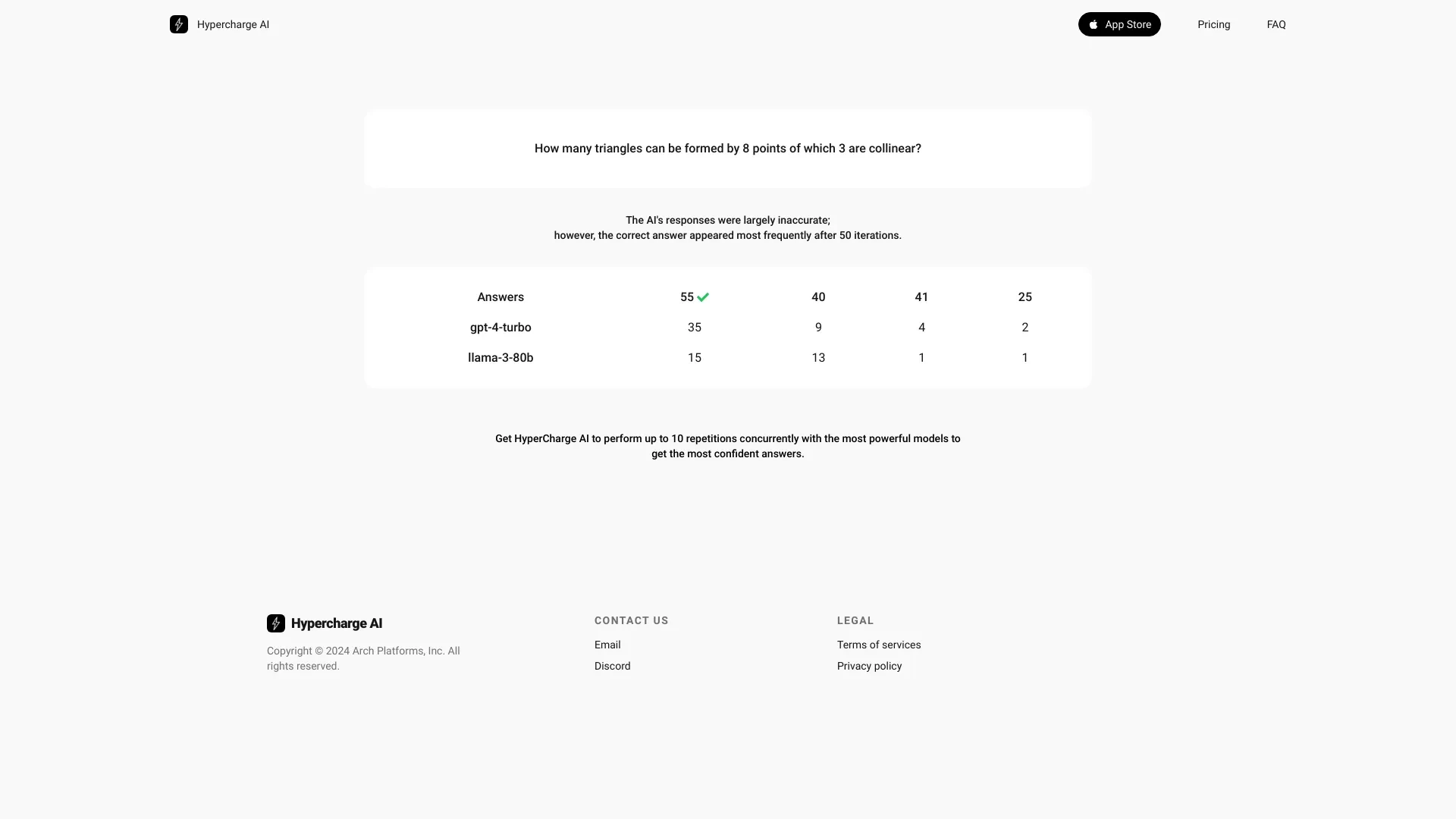
Validando resultados gerados por IA
Realizando testes de benchmarking em LLMs
Explorando engenharia de prompt complexa
Habilitando recuperação de dados organizada
Forças Chave
Acesso a múltiplos threads de IA simultaneamente
Interface de cartão horizontal amigável
Aplicação versátil em vários domínios
Recursos Principais
Acesso simultâneo a até 10 threads de chat
Exibição de conversas com fios em uma interface baseada em cartões
Suporte para vários prompts de LLM
Capabilidades aprimoradas de engenharia de prompts
Validação de saídas de LLM